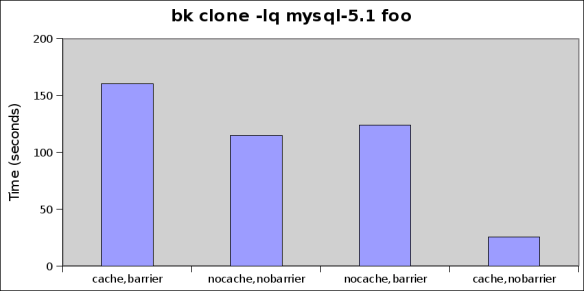
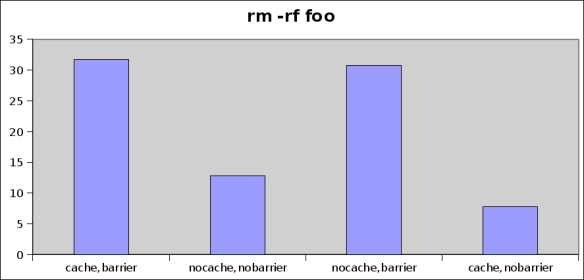
I’ve talked about disk space allocation previously, mainly revolving around XFS (namely because it’s what I use, a sensible choice for large file systems and large files and has a nice suite of tools for digging into what’s going on).Most people write software that just calls write(2) (or libc things like fwrite or fprintf) to do file IO – including space allocation. Probably 99% of file io is fine to do like this and the allocators for your file system get it mostly right (some more right than others). Remember, disk seeks are really really expensive so the less you have to do, the better (i.e. fragmentation==bad).
I recently (finally) wrote my patch to use the xfsctl to get better allocation for NDB disk data files (datafiles and undofiles).
patch at:
http://lists.mysql.com/commits/15088
This actually ends up giving us a rather nice speed boost in some of the test suite runs.
The problem is:
– two cluster nodes on 1 host (in the case of the mysql-test-run script)
– each node has a complete copy of the database
– ALTER TABLESPACE ADD DATAFILE / ALTER LOGFILEGROUP ADD UNDOFILE creates files on *both* nodes. We want to zero these out.
– files are opened with O_SYNC (IIRC)
The patch I committed uses XFS_IOC_RESVSP64 to allocate (unwritten) extents and then posix_fallocate to zero out the file (the glibc implementation of this call just writes zeros out).
Now, ideally it would be beneficial (and probably faster) to have XFS do this in kernel. Asynchronously would be pretty cool too.. but hey :)
The reason we don’t want unwritten extents is that NDB has some realtime properties, and futzing about with extents and the like in the FS during transactions isn’t such a good idea.
So, this would lead me to try XFS_IOC_ALLOCSP64 – which doesn’t have the “unwritten extents” warning that RESVSP64 does. However, with the two processes writing the files out, I get heavy fragmentation. Even with a RESVSP followed by ALLOCSP I get the same result.
So it seems that ALLOCSP re-allocates extents (even if it doesn’t have to) and really doesn’t give you much (didn’t do too much timing to see if it was any quicker).
I’ve asked if this is expected behaviour on the XFS list… we’ll see what the response is (i haven’t had time yet to go read the code… i should though).
So what improvement does this patch make? well, i’ll quote my commit comments:
BUG#24143 Heavy file fragmentation with multiple ndbd on single fs
If we have the XFS headers (at build time) we can use XFS specific ioctls
(once testing the file is on XFS) to better allocate space.
This dramatically improves performance of mysql-test-run cases as well:
e.g.
number of extents for ndb_dd_basic tablespaces and log files
BEFORE this patch: 57, 13, 212, 95, 17, 113
WITH this patch : ALL 1 or 2 extents
(results are consistent over multiple runs. BEFORE always has several files
with lots of extents).
As for timing of test run:
BEFORE
ndb_dd_basic [ pass ] 107727
real 3m2.683s
user 0m1.360s
sys 0m1.192s
AFTER
ndb_dd_basic [ pass ] 70060
real 2m30.822s
user 0m1.220s
sys 0m1.404s
(results are again consistent over various runs)
similar for other tests (BEFORE and AFTER):
ndb_dd_alter [ pass ] 245360
ndb_dd_alter [ pass ] 211632
So what about the patch? It’s actually really tiny:
--- 1.388/configure.in 2006-11-01 23:25:56 +11:00
+++ 1.389/configure.in 2006-11-10 01:08:33 +11:00
@@ -697,6 +697,8 @@
sys/ioctl.h malloc.h sys/malloc.h sys/ipc.h sys/shm.h linux/config.h \
sys/resource.h sys/param.h)
+AC_CHECK_HEADERS([xfs/xfs.h])
+
#--------------------------------------------------------------------
# Check for system libraries. Adds the library to $LIBS
# and defines HAVE_LIBM etc
--- 1.36/storage/ndb/src/kernel/blocks/ndbfs/AsyncFile.cpp 2006-11-03 02:18:41 +11:00
+++ 1.37/storage/ndb/src/kernel/blocks/ndbfs/AsyncFile.cpp 2006-11-10 01:08:33 +11:00
@@ -18,6 +18,10 @@
#include
#include
+#ifdef HAVE_XFS_XFS_H
+#include
+#endif
+
#include "AsyncFile.hpp"
#include
@@ -459,6 +463,18 @@
Uint32 index = 0;
Uint32 block = refToBlock(request->theUserReference);
+#ifdef HAVE_XFS_XFS_H
+ if(platform_test_xfs_fd(theFd))
+ {
+ ndbout_c("Using xfsctl(XFS_IOC_RESVSP64) to allocate disk space");
+ xfs_flock64_t fl;
+ fl.l_whence= 0;
+ fl.l_start= 0;
+ fl.l_len= (off64_t)sz;
+ if(xfsctl(NULL, theFd, XFS_IOC_RESVSP64, &fl) < 0)
+ ndbout_c("failed to optimally allocate disk space");
+ }
+#endif
#ifdef HAVE_POSIX_FALLOCATE
posix_fallocate(theFd, 0, sz);
#endif
So get building your MySQL Cluster with the XFS headers installed and run on XFS for sweet, sweet disk allocation.
Like this:
Like Loading...